
Responsive, resilient, elastic and message-driven applications are not longer being deployed just by a handful of early adopters like Netflix, Twitter, Google and Facebook.
In the previous article Why managing Reactive systems is keeping your Operations team up at night, we reviewed how Reactive application development becoming mainstream is leading to demands on Operations that are simply not met by yesterday’s software architectures and technologies.
Enterprises actively migrating or considering evolving parts of their systems towards microservice-based applications need a convenient way to deploy and manage everything. What’s needed is a system that is allowed to fail, isolating the issue gracefully without disrupting the user experience.
As a reminder, Martin Fowler’s blog post shows us the differences in approach between Monoliths and Microservices:

Although new system architectures require new approaches, little attention has been paid to how Operations is supposed to deploy and manage Reactive applications based on distributed, microservice-based architectures. Reactive applications continue being responsive and resilient in the face of failure by isolating and replicating new instances of microservices in a distributed architecture, where one point of failure does not strangle the whole system.
Tools like Amazon EC2, Docker, Puppet, Chef, Ansible and others that Operations use now are useful, but designed primarily for what the majority of enterprises are doing now: deploying single apps on monolithic servers. This leads us to identifying, broadly, three significant challenges that will continue to harass Operations with difficult, error-prone deployments:
Let’s go into a little more detail on this.
The demands placed on systems are ruthless nowadays. Starting with global expansion in mobile technology and continuing now with IoT, Operations deals with exponentially greater loads; yet for all their efforts, services provided by airlines, banks, retailers and telecommunications providers are still perceived to be sluggish. Imagine what just the next five years likely to produce in this 2020 projection of enterprise architectures:
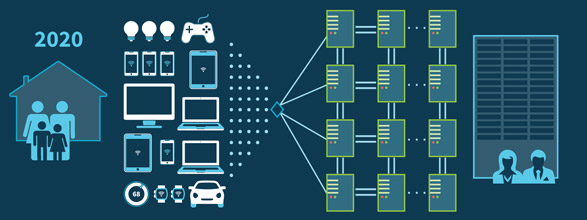
This presents a challenge for Ops: armed with the technologies of yesterday's monolithic systems, how can they manage completely new microservice-based architectures? Operations still battles with challenges when it comes to launching even a single app on a single server; without automation to ensure process repeatability, you are left with a higher likelihood of errors that lead to downtime.
When developing applications, experimentation in a dev environment is encouraged and relatively risk-free. Conversely, deploying and managing applications in production can be incredibly risky. Sometimes enterprises suffer so greatly that a drastic decision is made: in a recent poll of companies that dealt with unexpected downtime, 1 in 5 of them “let go” at least one employee as a result of the outage. There is little room for experimental improvements when any change to the status quo can have severe results.
This is why we see Reactive systems built to withstand failures gracefully and without resulting in downtime becoming more mainstream.
In response to these challenges, the market has embraced a handful of useful Ops technologies, e.g. Amazon EC2, Puppet, Chef, Ansible and many more. But enterprises soon discovered, especially with Reactive systems, that these tools and services are really best at supporting the infrastructure needs of a single application and server (or two). These tools are useful in many cases, but do not directly address the orchestration of a deployment to a cluster of 5 or 10 or 50 servers.
If you imagine the challenges of manually deploying a single app to a single server, then multiply that risk by N-servers to see what it’s like when deploying a Reactive system to a cluster, where a combination of Reactive and predictive scaling is often needed. Additionally, if anything goes wrong then a rollback of the whole deployment is necessary; being able to do so at the push of a button necessitates automation, versioning, immutable deployments and support for rolling upgrades. Without this type of set up, the risks and unpredictability of the roll-out can be huge in scope.
Operations need a more convenient and efficient alternative to managing custom scripts and a mashup of disparate tools. In addition to tools that help manage infrastructure, networks and OS, Operations needs coverage for the entire application cluster, prioritizing availability, resilience and long-term maintenance.
What makes a great user experience today? The list is long, but probably would start with Responsiveness (aka availability). At this very moment, your customers are doing everything they can to stretch your systems to the limit, and they don’t want to wait. In an age when extreme loads on servers make downtime more likely, it’s also more expensive than ever before. Here is some data on the real-life costs of service downtime:
Gartner published that the industry-recognized average cost of downtime is equivalent to roughly $5,600 each minute (over $300,000 per hour)
Avaya’s 2013 survey of over 200 IT professionals in large companies revealed that 80% of them lost revenue during downtime—the average was approximately $140,000 per hour, with financial sector companies losing an average of $540,000 per hour
For all the cost that goes with it, achieving 99.999% availability is prohibitively expensive for most enterprises. Monolithic system architectures cannot be up 100%; many of us remember how Knight Capital lost $440 million due to incorrectly processed trades during a failed deployment, killing the entire company in just 30 minutes.
Reactive applications managed are designed with the understanding that they will often fail--but gracefully, isolating and replicating faulty instances while maintaining system responsiveness, resilience and elasticity.
It’s not secret that the demands placed on systems are ruthless nowadays. Starting with global expansion in mobile technology and continuing now with IoT, Operations deals with exponentially greater loads; yet for all their efforts, services provided by airlines, banks, retailers and telecommunications providers are still perceived to be sluggish.
If enterprise development teams continue to build Reactive applications based on distributed microservice-based architectures without a convenient, simple way of deploying and managing them in production, Operations will continue to face the three pains described above.
Luckily, Typesafe is on the case. Stay tuned for more news, and have a Reactive Day!
